For Machine learning(ML), you deal with a large set of data with a lot of features. For instance, to predict housing prices, its features would be – an area of the land, number of rooms, size of rooms and kitchen, neighborhood, age of the building, land slope, proximity to the highway-railway-airport, etc.
The algorithm sees only numbers, not units.
Let’s take, 5-year-old building with 5 rooms of 500 square meter area. Here, the algorithm will see features as numbers- 5, 5 & 500. It will give the same importance to both features (Age of building and number of rooms) with the same value. Among them, 500 is much greater. So, It might give more importance to the area while predicting selling price. In other words, Features with higher values dominate the data. Subsequently, this could affect the outcome and efficiency of the algorithm. Therefore, We need to scale the values in nearly the same range. This process of scaling the data is called Feature Scaling.
To scale all the feature-values to the almost same range, there are different methods: broadly categorized in normalization and standardization. (Will discuss these methods in future articles)
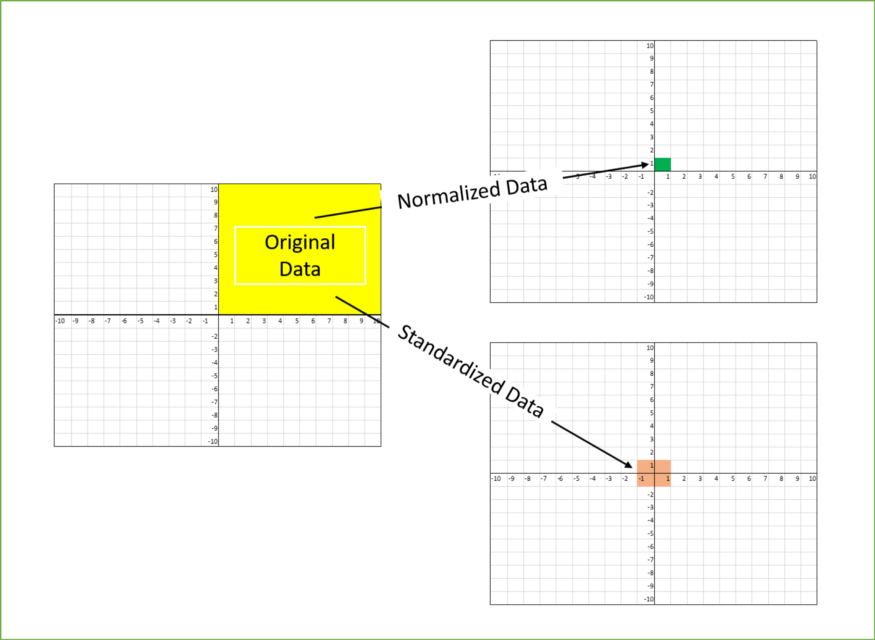
The image above shows, data scaled to (0 to 1) and (-1 to +1)
Its Importance for different algorithms
In machine learning, we use different algorithms. Feature scaling helps some algorithms. Here is a quick look:
(These are the names of the different algorithms. Explaining them in detail is beyond the scope of this article. keep it for some another time)
Gradient descent algorithms
ML algorithms – such as linear regression, logistic regression, neural network – uses gradient descent for optimization. They require data to be scaled.
Having features on a similar scale can help the gradient descent converge more rapidly toward the minima. Calculation speed increases.
Distance-based algorithms
Distance-based algorithms such as K-Nearest Neighbor, K-Means are most affected by the range of features. These methods use the distance between data points. Feature with higher values might be given higher weightage. This can impact the performance of the algorithm and we do not want our algorithm to be biased towards the specific features. Therefore,
Scale data before applying distance-based algorithms, so that all the features contribute equally to the result.
Endnote:
Scaling the features is a critical step in the pre-processing of machine learning. I will explore it more as I learn and apply algorithms to my projects.
I look forward to your input as to whether you have a unique experience in scaling features. Thanks for reading. Contact me @LinkdIn
Reference:
https://towardsdatascience.com/all-about-feature-scaling-bcc0ad75cb35
https://en.wikipedia.org/wiki/Feature_scaling